0.1 摘要
在使用LLM开源模型的过程中,仅仅对 Prompt Engineer 即 提示词工程 上面做功夫必然不能够满足工业领域较为复杂的应用场景。
对于本地开源LLM和本地开源RAG建立向量知识库,本文选择了2024年04月开源的RagFlow。
0.2 背景依托
博0阶段横向
-
为XUST开发自有LLM,并为后续相关横向项目积累经验。
-
工业大模型的定制化开发,满足其 可信性、实时性。
-
向量库的创建属于 "重复造轮子" 的工作,无非就是
- 选择一个向量库存储引擎
- 写一套PDF、Word、Txt文件的解析方法
- 挂一个本地
Embedding,并连接 - 做文本匹配接口
- 耦合本地LLM和以上创建的知识库
因此没有特殊需求,例如 定期爬虫 等特殊场景(其实开源的RAG框架也陆续支持这些特殊场景的知识工程了),没必要自己写一套。
0.3 更新日志
- 2024.10.26 完成第一章初稿
- 2024.10.29 完成第一章
- 2024.11.07 增加了一部分
- 2024.11.11 完成了初稿
0.3 架构概览
架构图
本文架构设计
- Docker:自编译,包含
Embedding全量模型。 - Ollama:用于挂在本地模型,本文架构主要使用Chat模型——Qwen2.5 14b
- RagFlow:主要使用了
PR#2865之前(不包含)的版本,后续版本由于WEB API混乱,暂不使用。 - 硬件配置:8C+4c Intel Core i7-12700F + Gigabyte B660M AORUS ELITE DDR4 + 32 GB DDR4-3200 + NVIDIA GeForce RTX 3060 (12 GB)
目录
1 知识库的设计
RAG的一般形式
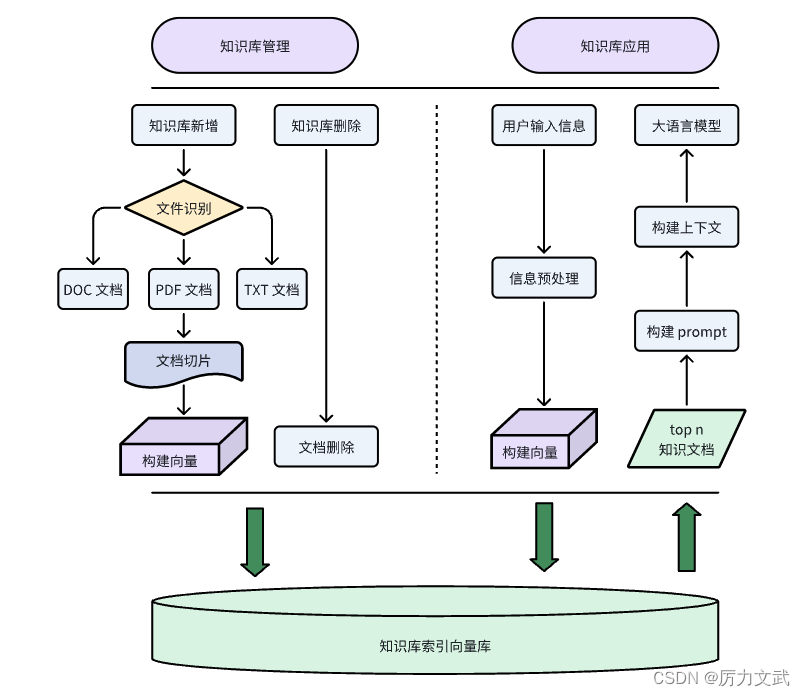
在本项目中,所输入的校级规章制度文件格式为Doc、PDF,正文内容文字格式标准规整,极少数文件有结构化数据(表格)。
-
知识库的设计着重在于以下两点:
- 向量库
- 文本库
-
1.1 文本库
实际就是按照一定切片逻辑将全文切片,每一片称之为
Chunk块 。这个
切片逻辑在RagFlow框架中已经内置,也是所选框架的特色所在。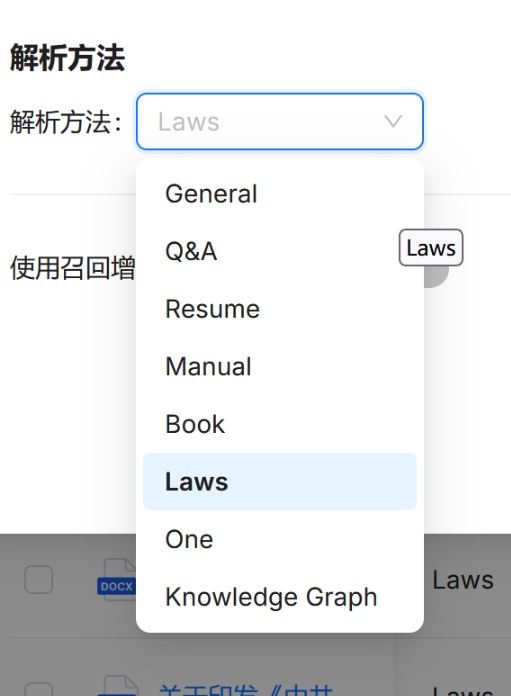
本人使用经验总结如下:
类型 适用文件格式 经验说明 General常规模式 DOCX, EXCEL, PPT, PDF, TXT, JPEG, JPG, PNG, TIF, GIF 对于部分特殊格式可以选用,通用性强带来了针对性差的问题,其实际分的Chunk似乎根本 没有根据语义 ,而是大致根据Token数直接 强行分开,导致对于连贯性或上下文有较强语义语境连贯性的文本无法理解好。 Q&A问答模式 EXCEL, CSV/TXT 类似于“微调”,其 准确性 极高,匹配到相应问题后会完整回答出来,此模式的适用范围极窄,有这类数据需求的不会选择RAG,不需要微调的也是要用RAG的相关生成特性,这个模式是一种丰富吧,个人认为是应对部分 敏感 问题的出现,强行把LLM掰回正规。 Manual手册模式 PDF 官方解释其适用于类似 使用手册、说明书 这一类文本,这类文本的特点是文本排版规整、图文并茂、上下文关联性较为清晰(说明书两个章节间基本上没什么联系)。实际测试过程中,Word文件格式也能进行解析,效果与Laws大致相似,但如果文档中存在表格,可能会抽风直接只解析表格。 Table表格模式 EXCEL, CSV/TXT 此模式会将结构化数据直接转换为结构化数据库中的内容,类似于MySQL,支持SQL语句 ,在内部运行时会由Embedding自动引导LLM生成SQL语句,由Embedding解释表头的含义。实际测试中效果不好,常常会出现 表头(字段)不完善、理解偏差、SQL执行失败的情况 (LLM生成的SQL语句有概率出现语法问题)。 Paper论文模式 PDF 顾名思义,上传一篇论文,此项目不考虑。 Book书籍模式 DOCX, PDF, TXT 大量的书籍,这个模式更多的是 总结知识,求准确性就算了 Laws法律条文模式 DOCX, PDF, TXT 这个模式是本人在此项目中选用的,因为本项目的校级规章制度符合法律条文分条分点、言语严谨的特点,此模式在分块时会按照正文中的章节分开 Presentation汇报PPT模式 PDF, PPTX 此项目不考虑。 Picture图片模式 JPEG, JPG, PNG, TIF, GIF 此项目不考虑。 One单块模式 DOCX, EXCEL, PDF, TXT 将整个文件的内容作为一个大块,好处是对于小文件能够直接保留所有上下文,保证知识的 连贯性;坏处是若文档较大有可能超过LLM最大理解长度 -
1.2 向量库
Embedding模型就是将文本转换为低维连续向量的过程算法,在推理时也存在 引导 LLM查询、理解的作用。
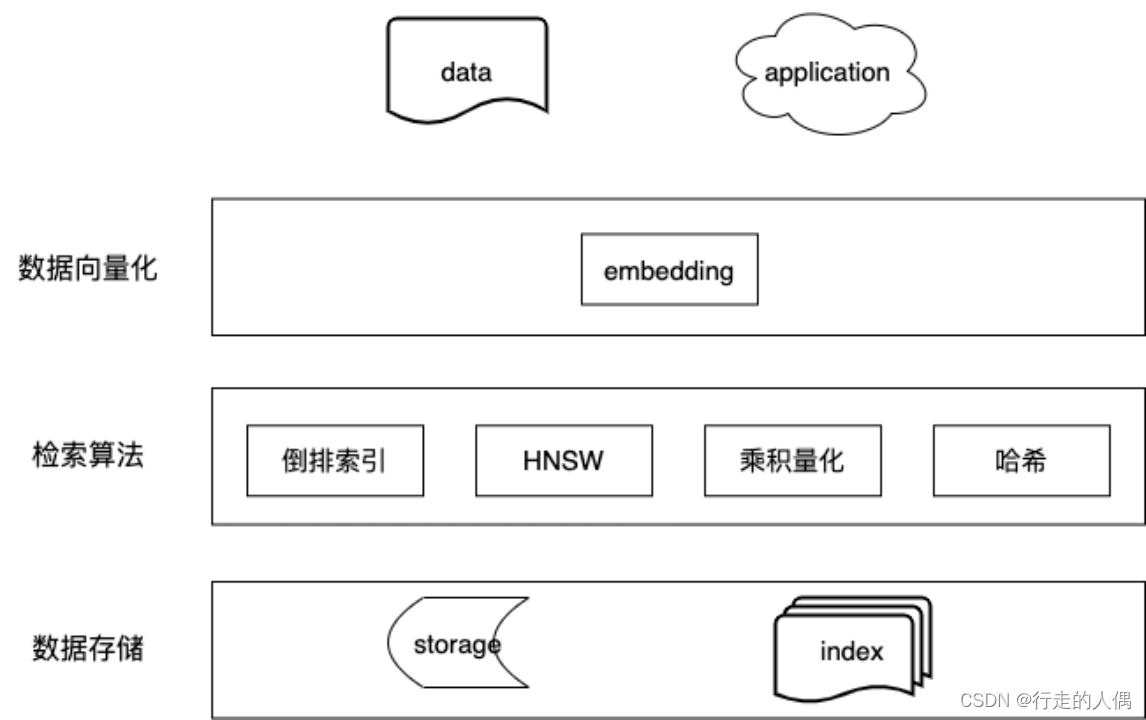
1.2.1 文件格式问题
-
RagFlow解析时不支持Doc老旧格式,需要手动另存为Docx对Word文件格式进行升级,否则会出现解析失败的情况,但其保存并不体现。(仅针对本文版本)
对于大量Doc文件的转换,这里引用网络资源,综合为以下VBA程序。
- 弹出选择框点选文件夹后自动遍历文件夹内doc文件,保存在同一级的XXX_docx文件夹中。
Sub main() Dim fso As New FileSystemObject '定义一个文件系统对象 Dim fld As Folder Dim xDlg As FileDialog Dim xDirNam As String Application.ScreenUpdating = False Set xDlg = Application.FileDialog(msoFileDialogFolderPicker) If xDlg.Show <> -1 Then Exit Sub xDirName = xDlg.SelectedItems(1) If fso.FolderExists(xDirName) Then '判断文件是否存在 Set fld = fso.GetFolder(xDirName) ScanDirs fld '调用函数 Else MsgBox "文件夹不存在" End If MsgBox "转换完成" Application.ScreenUpdating = True End Sub Sub ScanDirs(fld As Folder) '递归遍历文件夹 Dim fil As File, outFld As Folder '定义一个文件夹和文件变量 Set subfiles = fld.Files() '获取文件夹下所有文件 Set SubFolders = fld.SubFolders '获取文件夹下所有文件夹 ConvertDocToDocx fld.Path '检查根目录是否有需要转换的 For Each outFld In SubFolders '遍历文件夹 ConvertDocToDocx outFld.Path ScanDirs outFld '调用函数自身 Next End Sub Sub ConvertDocToDocx(xDirName As String) 'doc转换成docx Dim xFolder As Variant Dim xSaveFolder As Variant Dim xFileName As String xFolder = xDirName + "\" xSaveFolder = xDirName + "_docx\" If Dir(xFolder) <> "" And Dir(xSaveFolder) = "" Then MkDir xSaveFolder '判断文件夹是否存在,不存在则创建。 xFileName = Dir(xFolder & "*.doc", vbNormal) While xFileName <> "" Documents.Open FileName:=xFolder & xFileName, _ ConfirmConversions:=False, ReadOnly:=False, AddToRecentFiles:=False, _ PasswordDocument:="", PasswordTemplate:="", Revert:=False, _ WritePasswordDocument:="", WritePasswordTemplate:="", Format:= _ wdOpenFormatAuto, XMLTransform:="" ActiveDocument.SaveAs xSaveFolder & Replace(xFileName, "doc", "docx"), wdFormatDocumentDefault ActiveDocument.Close xFileName = Dir() Wend End Sub- 弹出选择框点选单个或多个Docx文件,自动保存到当前目录。
Sub doc2docx() 'doc文件转docx文件 Dim myDialog As FileDialog, oFile As Variant Set myDialog = Application.FileDialog(msoFileDialogFilePicker) With myDialog .Filters.Clear '清除所有文件筛选器中的项目 .Filters.Add "所有 WORD97-2003 文件", "*.doc", 1 '增加筛选器的项目为所有WORD97-2003文件 .AllowMultiSelect = True '允许多项选择 If .Show = -1 Then '确定 For Each oFile In .SelectedItems '在所有选取项目中循环 With Documents.Open(oFile) .SaveAs FileName:=Replace(oFile, "doc", "docx"), FileFormat:=12 .Close End With Next End If End With End Sub使用方法 新建一个Word,按下Alt++F11
1.2.2 解析方法的选择
- 本项目对解析的准确性、结构性有较高要求,因此正文使用
Laws方法,结构化数据使用Table方法。
1.2.3 Embedding模型的选择
-
经过测试,中文Embedding的参数量是硬道理,因此选择 BAAI/bge-large-zh-v1.5 。
注意:Hugging Face上的Embedding模型排名基本无意义,Embedding本身对语言就较为敏感,国产Embedding得分必然高于原生英文或其他语言的Embedding。
-
本文使用的 BAAI/bge-large-zh-v1.5 来自RagF全量Docker编译模式中的预置模型。实际测试效果与Ollama自己本地挂此模型的效果 基本无差别。实际使用中由于Ollama对模型二进制转化,必然存在精度、召回率等方面 一定程度的衰减。
-
不推荐使用GPU运行Embedding,实际速度并没有太大提升,且由于Chat模型也使用GPU运算,可能出现 爆显存 或Chat与Embedding 同时卡顿 的情况。
1.2.4 召回增强RAPTOR策略
在本项目的场景中不推荐启用,因为此功能实质上是让LLM自己先对原文有大致总结理解,然后根据此总结构建Chunk。此方法能够有效提升检索相应相关段落的能力,但是规章条例的语言和上下文紧密型极易导致LLM总结出现偏差,从而影响后续生成。
1.2.5 相似度阈值
此框架使用混合相似度得分来评估两行文本之间的距离。
$$混合相似度=\alpha \cdot 关键词相似度+\beta \cdot 余弦相似度$$ 其中,$\alpha+\beta=1$。- 关键词相似度类似BM25文本相关算法,直接从字符关键词角度进行匹配;
- 余弦相似度即为 向量库匹配 的一种向量匹配算法模式。
如果查询和块之间的相似度小于此阈值,则该块将被过滤掉。
实际使用过程中,可以选择较小阈值如0.2等,以防止信息量少的问题不被知识库“忽视”。
1.2.6 关键字相似度权重
即上一点中的$\alpha$,在实际测试中,似乎更高一点效果更好。
虽说原则上向量库权重高一点更好,但实际上文本向量化依旧是文本经过降维后的特征,此特征不能表征真正的关键字,两者结合能够实现速度与效果的共同提升。
1.2.7 Rerank模型
使用$rerank评分$代替矢量余弦相似性,由于此模型不同于余弦相似度、欧氏距离等纯数学算法,又是一种深度学习模型,会导致运行性能直线下降,甚至在知识库较大或前一流程匹配的Chunk较多时出现 超时、宕机 等情况。
不考虑性能影响,单独对结果进行评估发现,效果没好多少,甚至有些情况下效果更差。
1.2.8 Top N
相似度得分高于相似度阈值的Chunk中,取前$Top N$个送给LLM参与推理。
这个数值不宜太大,因为过大会导致超过LLM的最大理解长度;排名靠后的Chunk本身匹配度就不高,容易扰乱LLM的判断。建议根据知识库中Chunk的大小,综合长度不超过1000 Token,否则会出现不相关知识扰乱模型作答的情况。
2 Agent与Workflow
2.1 不是哥们儿,他俩啥关系?
OpenAI 应用人工智能研究负责人Lilian Weng在其Blog中将LLM Agent定义为LLM、记忆(Memory)、任务规划(Planning Skills)以及工具使用(Tool Use) 的集合。
其中 LLM 是核心大脑,Memory、Planning Skills 以及 Tool Use 等则是 Agents 系统实现的三个关键组件。
通过LLM和三个关键组件,LLM Agent可以拥有复杂的工作流程,其中模型基本上是与自身对话,而无需人工参与到交互的每个部分。
LLM Agent通过迭代运行并定义一些新的目标/任务,而非传统GPT那般接受单个查询的输入并返回输出
因此,LLM Agent 的WorkFlow工作流通常是一个迭代运行的过程。他俩还真是 哥们儿。
2.2 $Agent/WorkFlow$自定义模块的使用经验
本人架构
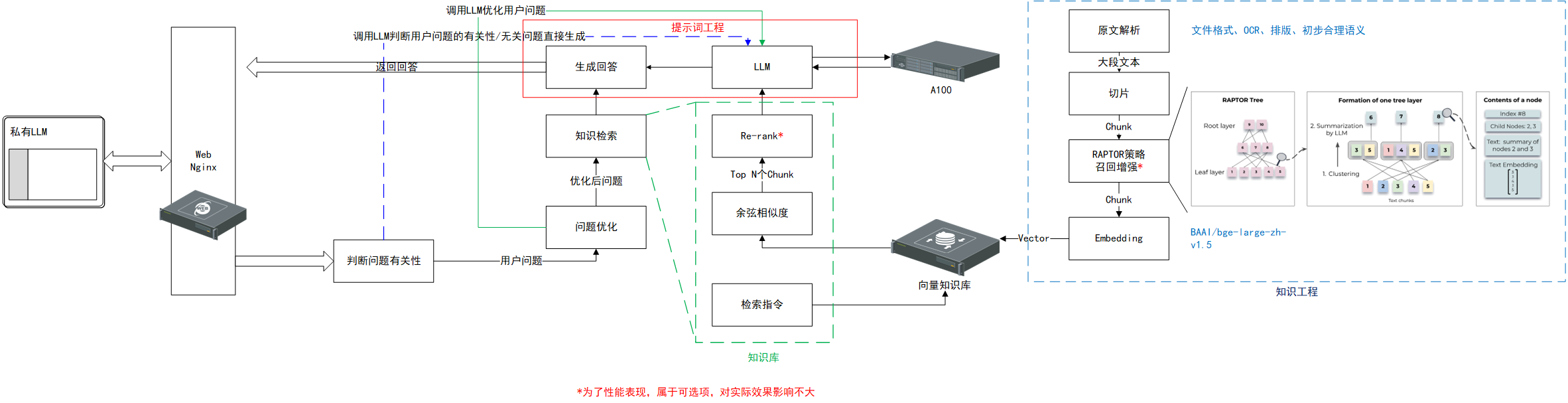
2.2.1 问题优化
食之无味,弃之可惜。
调用LLM对用户的问题进行优化,通常是完善语义或扩展问题(而非细化问题),由于此阶段不调用知识库,因此较为鸡肋,且随着迭代次数的增加,其优化后的问题可能偏离用户本意。
优化一次用户问题-->用优化后的问题检索一次知识库-->若检测不到就再来一次。
$eg1.$
原始问题:国家奖学金的基本条件
优化后回答:国家奖学金的基本条件有哪些?需要注意什么事项?
由此可见,其对问题的优化更多地是“废话文学”,这对于本身就不能在知识库中匹配到Chunk的原始问题其实没有太大作用。
2.2.1.1 对鸡肋的解释
向量知识库的匹配算法为
$$总分数=\alpha\cdot余弦相似度+\beta\cdot关键词相似度$$ 其中 $$\alpha+\beta=1$$问题优化过程中对 余弦相似度 、 向量相似度 都没有实质影响,所以能够匹配到Chunk的原始问题用不到这个模块,不能匹配Chunk的原始问题用这个模块也解决不了什么问题。
2.2.2 知识检索
对此,请先阅读前置公式。
对于 相似度阈值 、 关键词相似度权重 、 $Top N$ ,在之前的文章中均有解释,这里不再赘述。
- 经验1:所检索的知识可以用Key在后续的 生成回答 中嵌入到Prompt中,也可以不嵌入,似乎在流程传递过程中已经在Json中作为一个对象属性了。
- 经验2:无论是否将检索的知识嵌入到后续生成回答的Prompt中,都会占用Token长度。因此如果所连接的LLM运行框架对输入的Token有一定的限制,会导致截断、遗忘,从而使回答发生灾难性错误。
- 经验3:$Top\enspace N$的数量不宜过大,可以先行在知识库中进行 命中测试 ,人工经验得出最大第几个才能找到正确答案。过大将导致
ollama服务内置上下文长度为2048,且无法通过传参的方式修改(因此使用ollama时,总Token数量设置无法生效),导致相关信息被截断,从而影响问答效果。
解决方案为手动调整大模型参数并重新编译为一个新的模型。
首先将待修改模型的模型配置文件导出
ollama show --modelfile qwen2:72b > Modelfile
然后使用vim修改Modelfile,添加一行
PARAMETER num_ctx 32000
使用修改后的模型配置编译一个新的模型并存入Ollama的本地仓库
ollama create -f Modelfile qwen2:72b_ctx32k
2.2.3 生成回答
生成回答的提示词需要 对症下药 ,不同模型的提示词风格不同。
对于大量的知识检索结果,构建一个 思维链 让大模型先对知识进行筛选、判断是目前效果最好的方式。
例如以下思维链形式可供参考。
你是AAA,你只能依据后文给你的参考文本材料回答用户问题,不能使用自己的知识,严格按照要求作答。
你的工作是根据参考文本材料的内容以及文本材料的文件名称,一步一步地思考,按照以下步骤和要求完成任务。
以下是要求:
1、首先默认用户的所有问题都是在询问参考文本材料中的相关规定,不能用其它知识进行作答。
2、然后针对用户提出的问题找到参考文本材料中的依据,注意专业名词的准确性,如果有多个相关的依据,请分别作答。
3、然后请用找到的依据原文作为依据,开始解答用户问题的答案,回答时合理分段,找到的每个相关依据使用以下格式:"根据XXX的相关规定:XXX(原文)。因此XXX(简要解答用户问题)。"
4、然后猜测三个用户接下来想问的问题,分段换行回答,使用以下格式:"如果回答不够准确或检索的文件不正确,猜测您可能想追问的问题有:1.XXX?"
5、最后换行输出以下结束语:"AAA"
以下是参考文本材料
{input}
文章的 AAA 为涉密内容,不公开。