0.1 摘要
在使用LLM开源模型的过程中,提示词Prompt固然重要,但在工作流WorkFlow的开发中需要对运行时(推理时)相关超参数进行一定地经验调整。
本文对LLM推理过程中常见的超参数进行通俗解释,其中不乏由于个人对LLM基础知识不牢所带来的理解错误,您可以在评论中指出。
0.2 背景依托
博0阶段横向
- 为XUST开发自有LLM,并为后续相关横向项目积累经验。
- 工业大模型的定制化开发,满足其 可信性、实时性。
目录
1 超参数
1.1 对定义的通俗解释
- 不依赖于训练的、人为控制的参数
- 用于调优
- 多为经验使然
1.2 常见的超参数
图中为RagFlow在配置WorkFlow中Agent的
生成回答模块或Chat助理时的运行时超参数
以下将对上图中的运行时超参数进行解释。
1.2.1 $Freedom$自由度
这是RagFlow项目自带的 自由度 预设模式,而 非真正意义上的超参数。
其预设参数如下:
| 模式 | $Temperature$ | $Top P$ | $Presence Penalty$ | $Frequency Penalty$ | $Max Tokens$ |
|---|---|---|---|---|---|
| 即兴创作Improvise | $0.90$ | $0.90$ | $0.40$ | $0.20$ | $512$ |
| 精确Precise | $0.10$ | $0.30$ | $0.40$ | $0.70$ | $512$ |
| 平衡Balance | $0.50$ | $0.50$ | $0.40$ | $0.70$ | $512$ |
当前数据来源于
PR#2865之前,后续版本由于WEB API混乱,暂不使用。
1.2.2 $Temperature$温度
本参数用于调整LLM生成文本的 随机性 ,在工业大模型的应用角度看,就是LLM输出结果的 稳定性。
1.2.2.1 原理探讨
LLM是生成式AI,对文本的生成并非严格意义上的“理解”,而是计算即将出现的下一个词/字(以下简称为Token)的 概率分布 。计算出所有下一个可能出现的Token的概率后,使用 既定 的 采样策略 选择出最终要输出的Token。
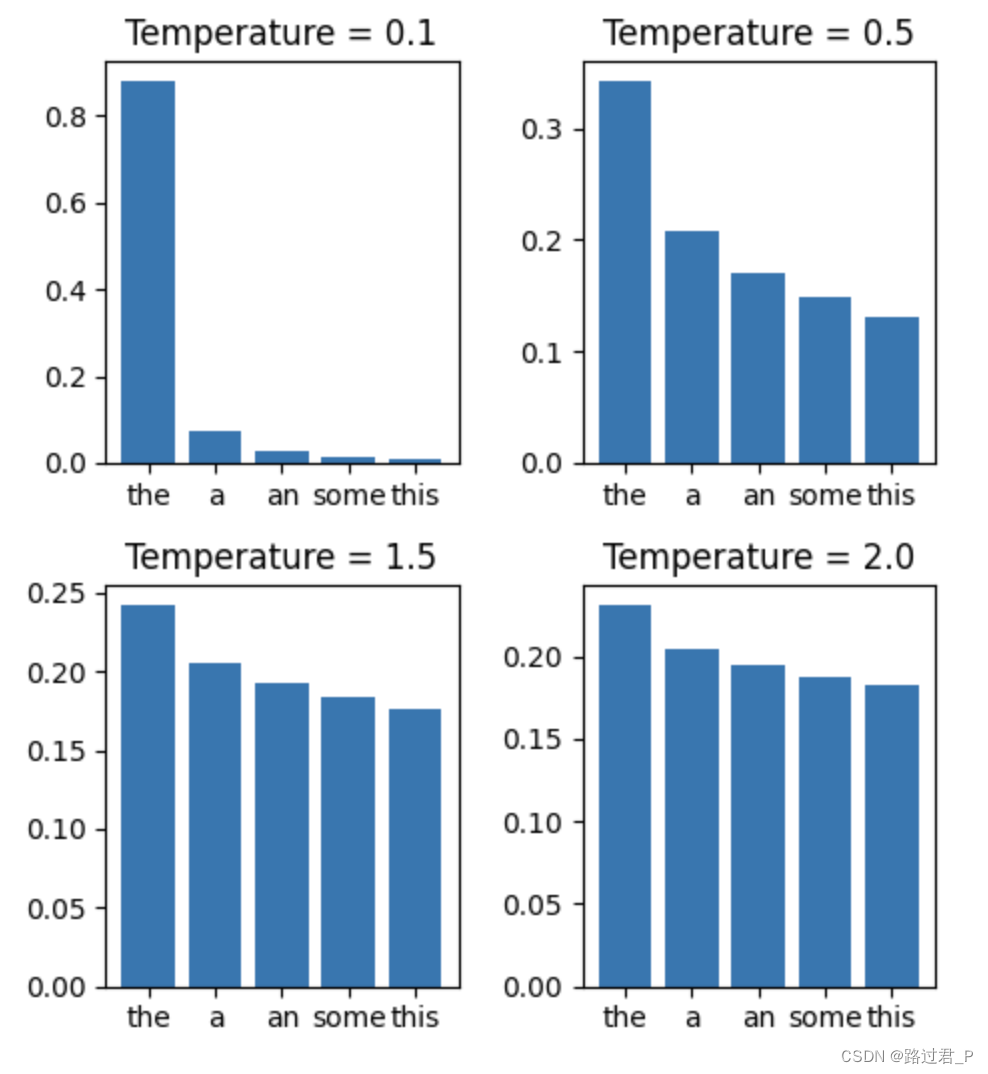
 $Temperature\in[0,1]$,在采样策略阶段对每个Token的概率进行调整,控制生成文本的多样性(越高越多样)和可预测性(越高越不可预测)。
$Temperature\in[0,1]$,在采样策略阶段对每个Token的概率进行调整,控制生成文本的多样性(越高越多样)和可预测性(越高越不可预测)。
 对原始概率的调整:
对原始概率的调整:
其本质就是一个带有额外缩放参数$Temperature$的SoftMax函数。
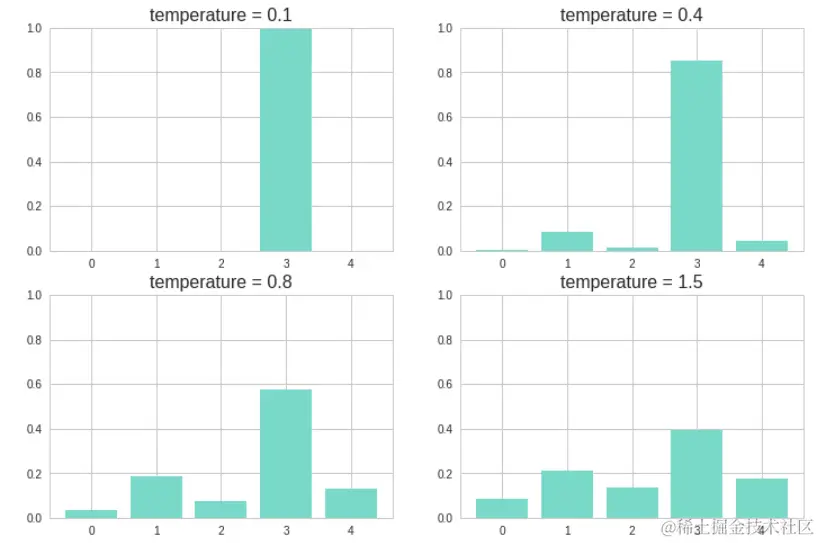
- Temperature越小,概率值越集中,或者说它放大了具有较大概率值的单词的概率,从而对最可能得结果进行了凸显。
- Temperature越大,概率值越平滑,或者说不同单词之间的概率值差别越小,从而带来了更多的可能性。
1.2.3 $Top\enspace P$核采样
本参数可以视作一种替代$Temperature$的采样方法,用 累计概率阈值 从另一视角对LLM输出的 多样性 进行配置。
1.2.3.1 原理探讨
官方文档指出
We generally recommend altering this or temperature but not both.
建议此参数与$Temperature$参数不要同时更改。
1.2.3.2 累计概率
对所有可能的Token降序排序,从最高的概率开始向下累加,即为累计概率。
$$累计概率=\sum_{i=1}^{k}P(w_i)$$ 其中,$k$应当满足 $$k=min\enspace a|\sum_{i=1}^{a}P(w_i)\geq Top\enspace P $$ 也就是指明$k$是累计概率达到阈值的最小词汇数量。两公式中,$P(w_i)$表示第$i$个词的概率。
因此,被囊括进$k$的Token进入候选集,随机选一个作为下一个输出Token。
由此可知,刚才提到的 累计概率阈值 就是$Top\enspace P$
1.2.4 $Frequency\enspace Penalty$频率惩罚
这里先讲频率惩罚,以便于存在惩罚的理解。
这是对已输出词进行重复性角度的惩罚,降低对输出中常见词的出现概率,从而鼓励新词的出现。
其惩罚程度与该常见词出现次数成正比。
其值域分为两个区间
- $Frequency\enspace Penalty\in (0,1]$时,重复词会因为惩罚而出现地越来越少。
- $Frequency\enspace Penalty\in [-1,0)$时,重复词会因为“惩罚”(此时实质上是激励)而出现地越来越多。
1.2.5 工作原理
不同LLM模型在其具体实现细节上存在差异,以下是基本思想
假设有一个可能出现的词$t_i$,其已出现频率为$f(t_i)$则
$$P_{adj}(t_i)=P_{adj}(t_i)\cdot e^{-Frequency\enspace Penalty\cdot f(t_i)}$$经过计算后的概率参与选择。
这里可以看到,其已出现频率$f(t_i)$越高,惩罚强度越大。
当RAG知识库中存在大量重复专有名词时,不建议配置此参数。
1.2.6 $Presence\enspace Penalty$存在惩罚
与 频率惩罚 类似,作用相同,但其惩罚程度是固定的。
即,一个词已出现1次和已出现10次的惩罚程度相同。
当RAG知识库中存在大量重复专有名词时,不建议配置此参数。
1.2.7 $Max\enspace Tokens$最大$Token$数
Token计数方法

在调用LLM时,此参数用于规定输出时的最大Token数量,若发生提示词不符合模型的推荐形式导致模型发生不可控连续输出且不触发自我截断的情况,当输出$Token$的数量到达此规定值,则由运行框架(例如Ollama等)进行强制停止。