0.1 摘要
在使用LLM开源模型的过程中,仅仅对 Prompt Engineer 即 提示词工程
上面做功夫必然不能够满足工业领域较为复杂的应用场景。因此本人决定重构一套架构,这并不是造轮子,更不是法轮功,而是以 松耦合 的应用视角把组件视为服务。
本文部分引用了2024年04月开源的RagFlow。
0.2 背景依托
博0阶段横向
-
为XUST开发自有RAG,并为后续相关横向项目积累经验。
-
工业大模型的定制化开发,满足其 可信性、实时性。
-
向量库的创建属于 "重复造轮子" 的工作,无非就是
- 选择一个向量库存储引擎
- 写一套PDF、Word、Txt文件的解析方法
- 挂一个本地
Embedding,并连接 - 做文本匹配接口
- 耦合本地LLM和以上创建的知识库
因此没有特殊需求,例如 定期爬虫 等特殊场景(其实开源的RAG框架也陆续支持这些特殊场景的知识工程了),没必要自己写一套。↑这是之前嚣张的气焰。
↓瞬间老实
2024.11.17更新:千万不要乱立Flag。
0.3 更新日志
- 2024.11.17 提出架构私有化构想,并在组会上通过提案。
- 2024.11.23 完成对知识库、Docx解析、常用组件进行优化性质的重构。
- 2024.11.26 完成了文档前三章。
- 2024.11.27 完成了文档的初稿。
- 2024.11.30 增加流式输出API。
- 2024.12.01 编写所配套的VUE解析器
- 2024.12.02 优化API示例,优化并发能力,进行压力测试
0.4 版权说明
对版权的声明与探讨
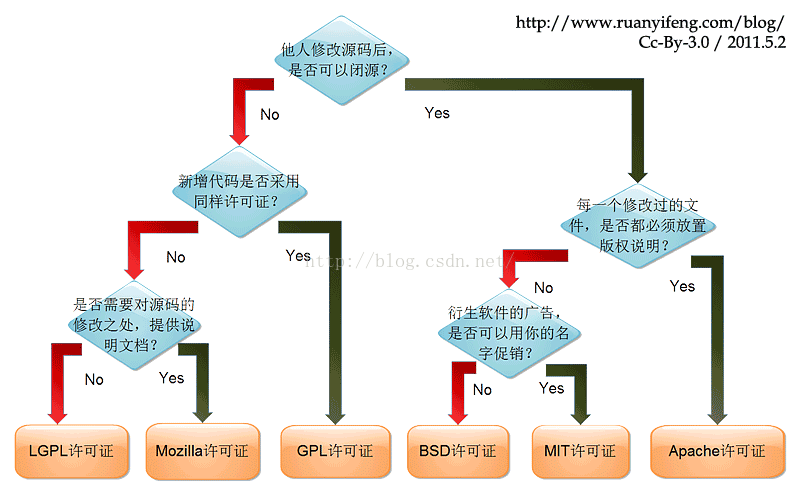
保护知识产权就是保护创新
本人深刻认识到知识产权的重要性,所引用的源码大多为Apache许可,因此本框架继续使用Apache许可。
2024.11.26日组会更新:采取Apache许可的闭源模式。
0.5 架构概览
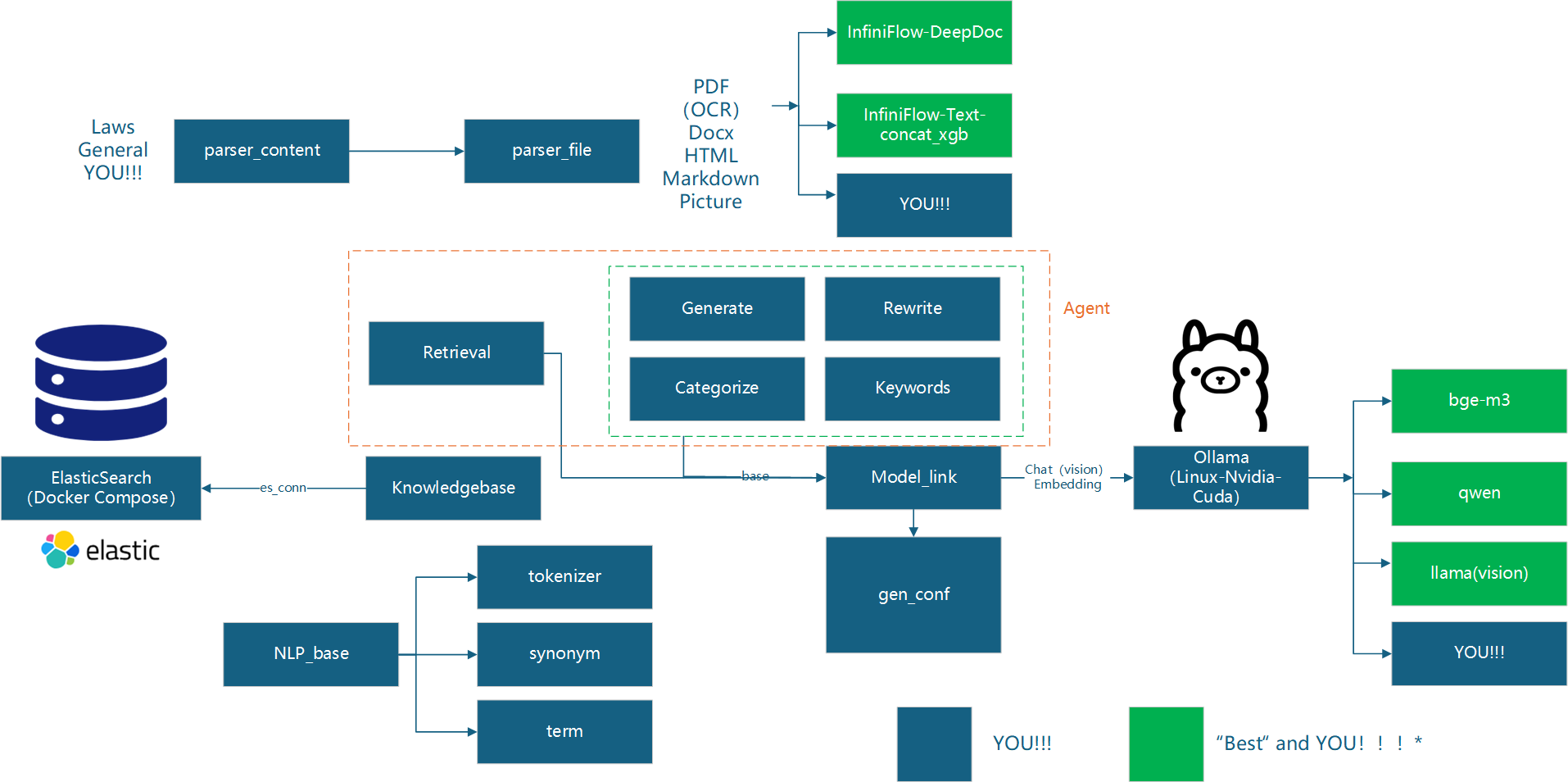
目录
- 0.1 摘要
- 0.2 背景依托
- 0.3 更新日志
- 0.4 版权说明
- 0.5 架构概览
- 目录
- 1 环境准备
- 2 知识库的配置
- 3 模型的配置
- 4 文件内容解析
- 5 Agent WorkFlow工作流
- 5 SSE流式输出的VUE解释器
- 6 API构建示例
- 7 性能评估
- 8 工作总结
1 环境准备
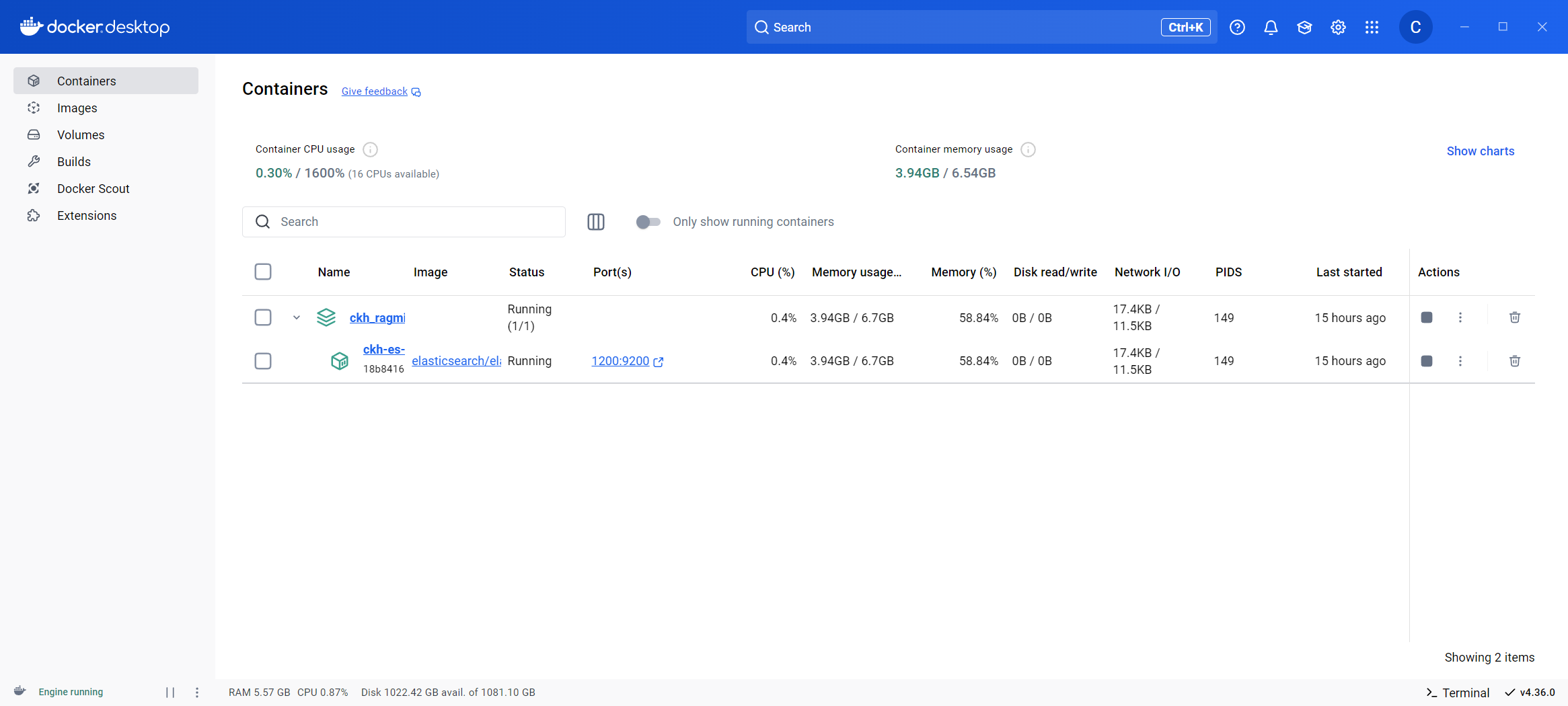
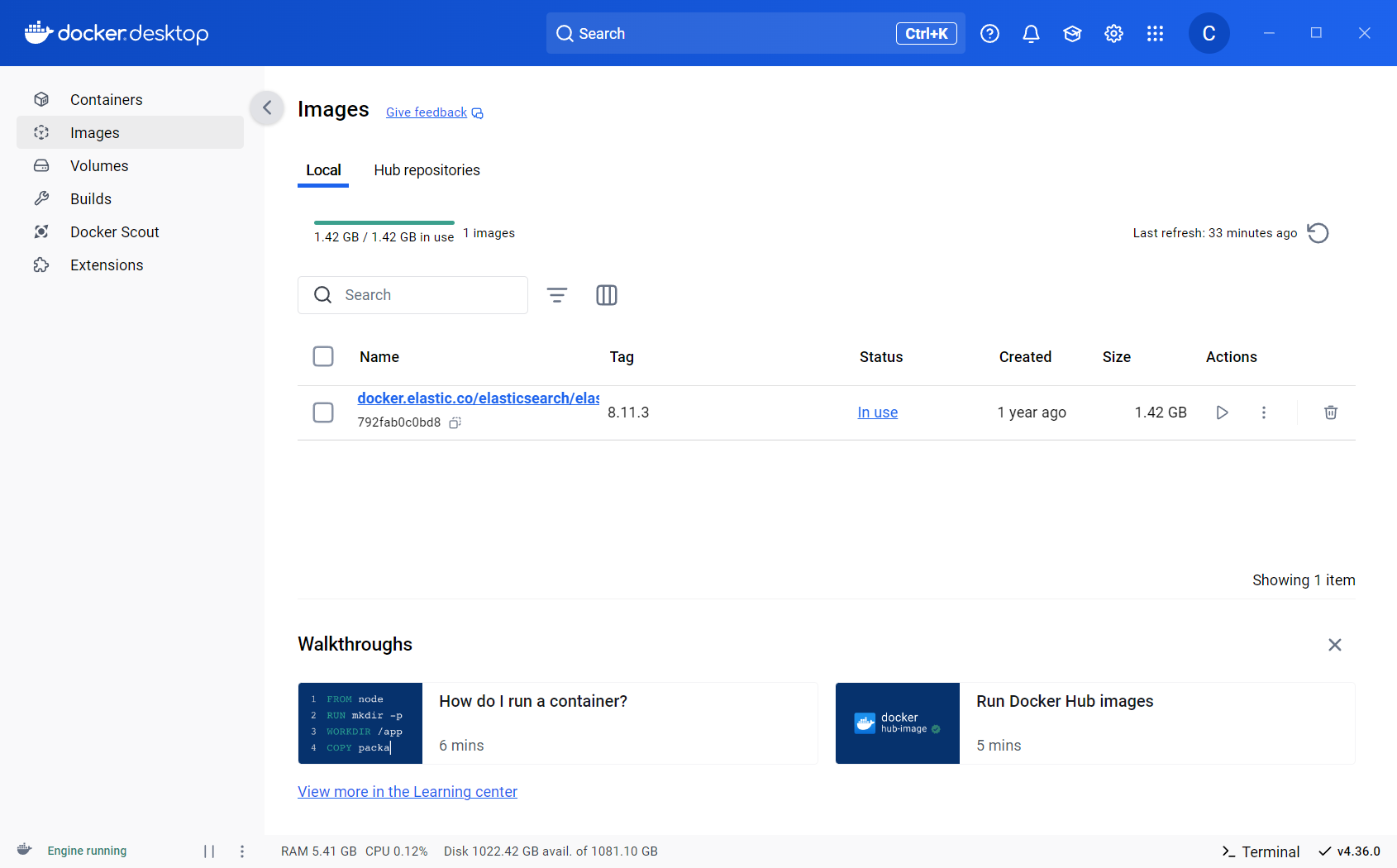
1.1 ElasticSearch的配置
如果你还没在自己的电脑上配置Docker (Windows, Mac, or Linux) ,请看Install Docker Engine。
在项目根目录下Powershell中运行
docker compose --project-name 自定义项目名 -f kb-docker-private.yml up -d
以Windows为例,运行命令时由于会下载ElasticSearch镜像,需要科学上网 ,也可以使用国内镜像站。
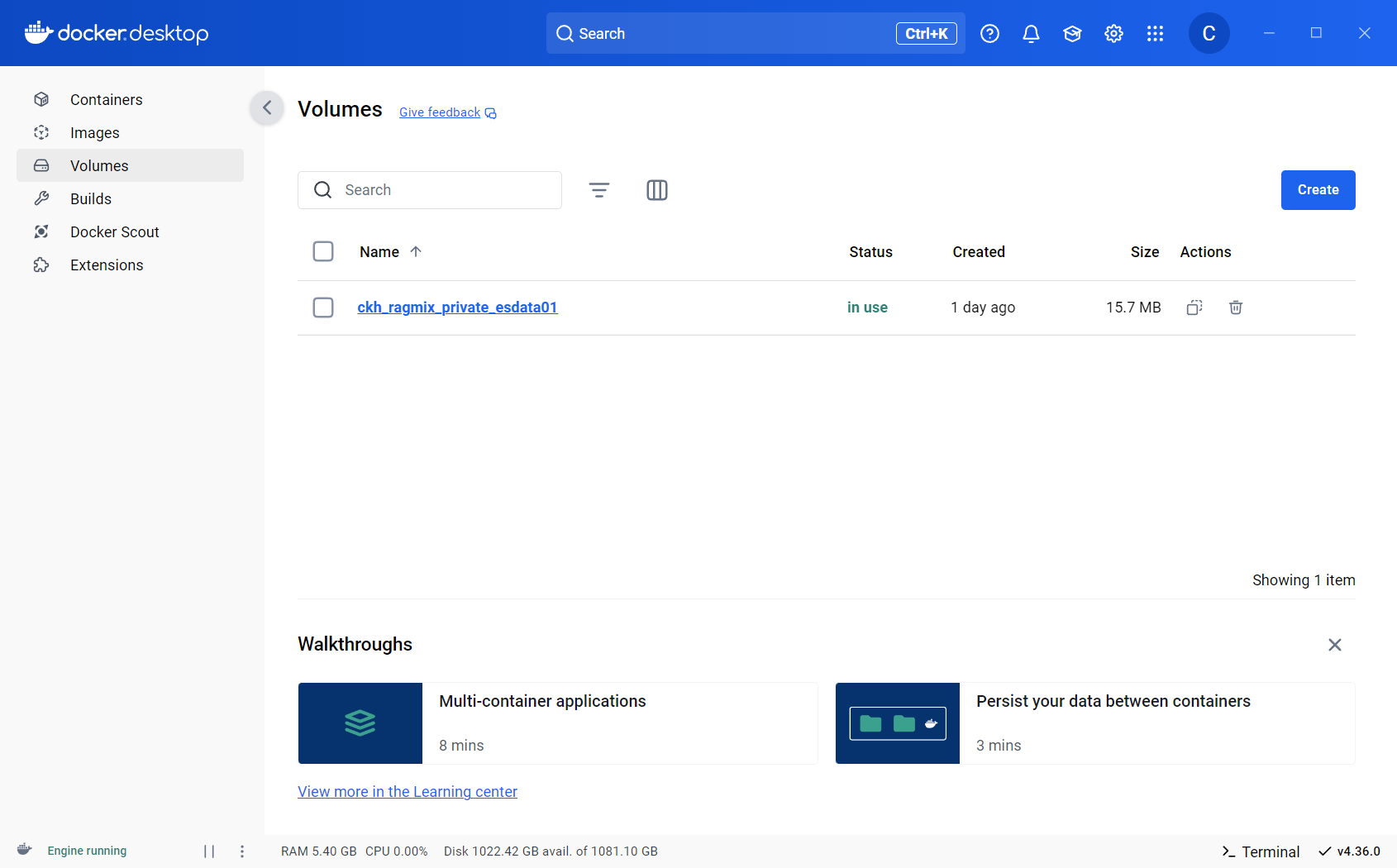
安装完成之后,在Docker Desktop上的Containers、Images、Volumes会出现以下项目,本文示例项目名为ckh_ragmix_private。
1.2 Python环境创建与配置项
Python请选择 3.12.7 64位版本。
推荐使用Anaconda。
在虚拟环境下运行
pip install -r ./requirements.txt
或直接使用Conda创建虚拟环境 (推荐)
conda env create -f environment.yml
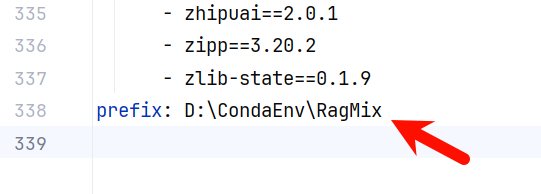
运行前注意修改
environment.yml最后prefix配置项,可以之间删除338行,也可以修改为你的Conda环境路径,注意为空文件夹。
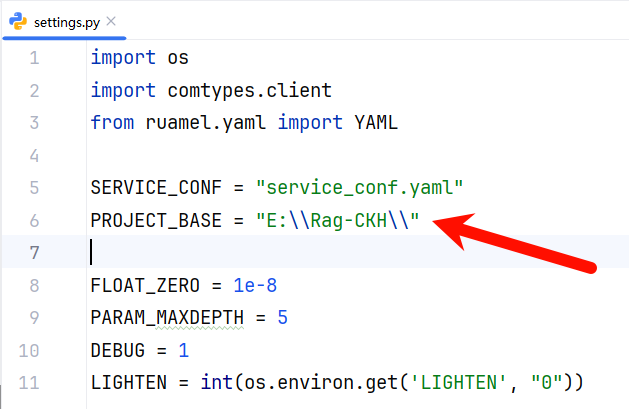
依赖安装完成之后,修改根目录下settings.py中的 PROJECT_BASE 变量值,修改为项目所在 绝对地址,使用 双反斜杠 。
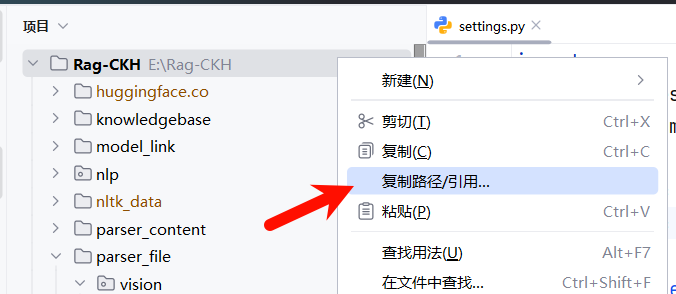
可以在Pycharm中右键项目根目录,选择
复制路径/引用,复制绝对路径,然后改为 双反斜杠 ,并在结尾加上 双反斜杠。
再运行根目录下的download_deps.py,下载所需的内置模型文件,可能需要 科学上网。
接下来请按照顺序阅读。
2 知识库的配置
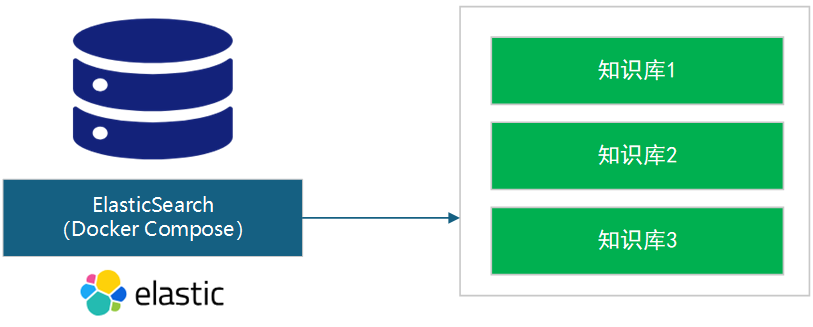
2.1 知识库的新建
不同知识库通过知识库名(knowledgebase_name或idxnm)划分。 以下是新建知识库的示例代码
from knowledgebase.link import ELASTICSEARCH
knowledgebase_name = "ckh" # 知识库名称
# 判断知识库是否存在,否则创建新知识库
import json
from settings import get_project_base_directory
import os
if not ELASTICSEARCH.indexExist(knowledgebase_name):
ELASTICSEARCH.createIdx(knowledgebase_name, json.load(
open(os.path.join(get_project_base_directory(), "knowledgebase/mapping.json"), "r")))
其中引入的 ELASTICSEARCH 保证了与Docker中ElasticSearch的连接,引入即连接。
2.2 连接远程知识库
修改 service_conf.yaml 中的hosts、username、password配置项即可。
2.3 知识库的可视化管理*
此部分内容属于选读内容。
ElasticSearch也是一种数据库,没有可视化界面用于管理,只能编写指令(ES使用POST指令)管理和查询,这里推荐几个好用的第三方可视化管理工具,仅供参考。
-
es-client:使用方便,推荐以浏览器插件的形式安装,本文后续也将以此工具为教程。
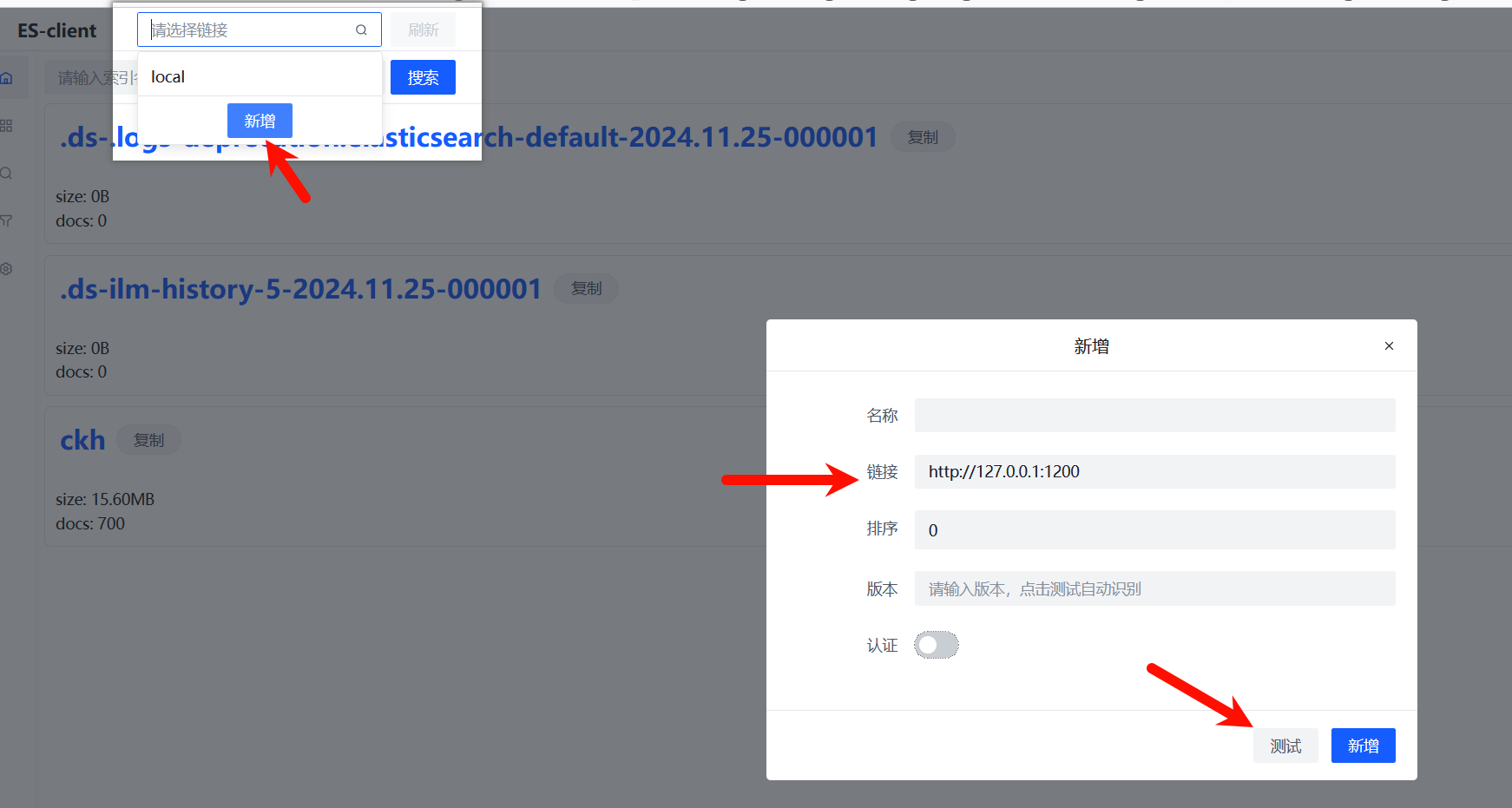
注意:服务器地址端口一般情况下为1200,具体请查看Docker端口对9200的映射。
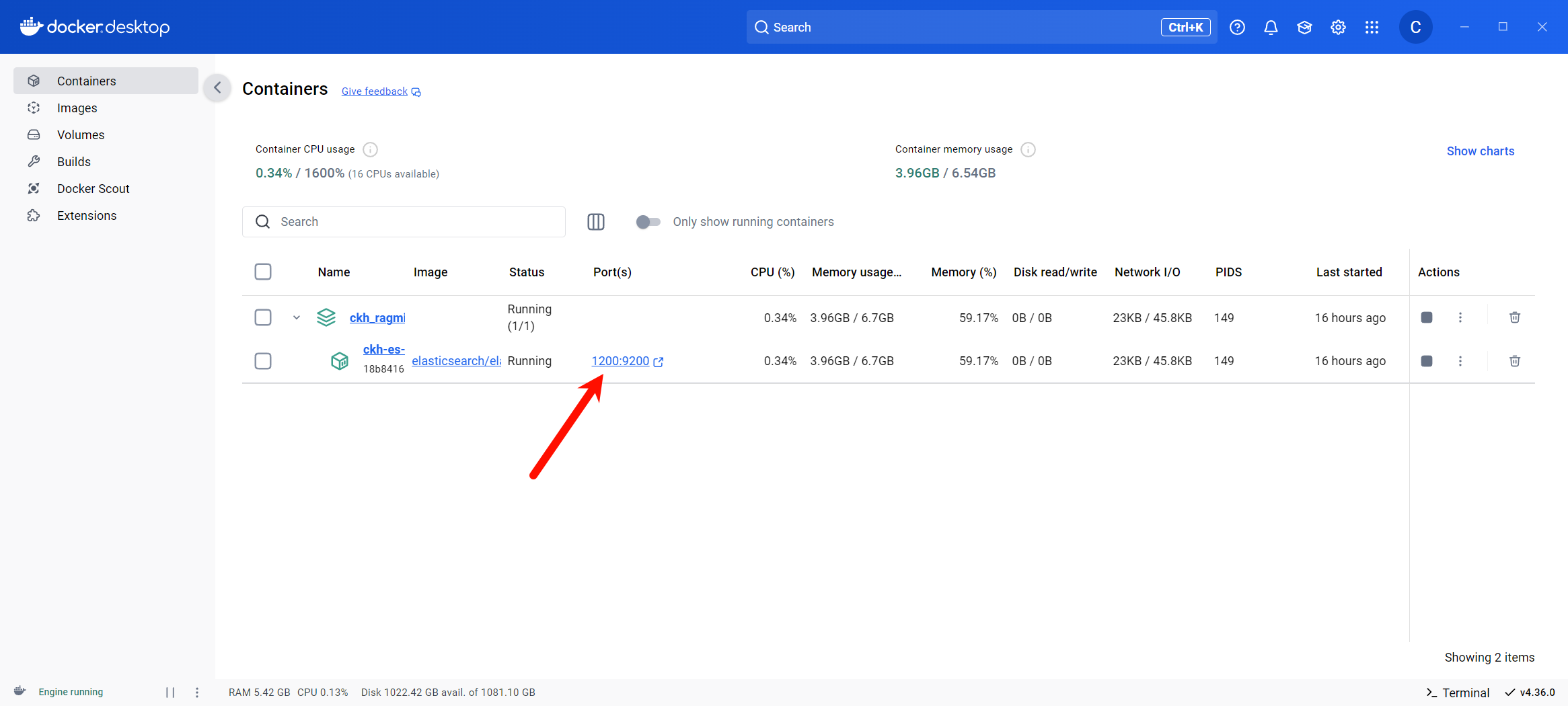 总库账号为elastic
总库账号为elastic总库密码为ckh
此配置在
kb-docker-private.yml中的ELASTIC_PASSWORD。
3 模型的配置
本架构支持连接Ollama中的模型,包括Chat、Embedding、Rerank、Vision。对其的封装也是本架构的一个特色,在这里我们称之为
模型对象,本架构可以直接将模型对象作为实参传入进行灵活调用。
那么,如何创建一个模型对象呢?
Embedding
from model_link.OllamaEmbedding import OllamaEmbed
ollama_embedding = OllamaEmbed(model_name="bge-m3", base_url="172.20.200.181:11434")
Chat
from model_link.OllamaChat import OllamaChat
ollama_chat = OllamaChat(model_name="qwen2.5:32b_ctx32k", base_url="172.20.200.181:11434")
Vision
from model_link.OllamaChat import OllamaChat
ollama_vision = OllamaChat(model_name="llama3.2-vision", base_url="172.20.200.181:11434")
其中的model_name是Ollama中的模型名称,base_url是Ollama所运行主机的地址,若是在本机运行,可以使用127.0.0.1:11434。
若在校园网环境,可以连接A100服务器上本人已经部署好的模型(host=172.20.200.181:11434),具体提供以下选择。
| NAME | ID | SIZE |
|---|---|---|
| llama3.2-vision:latest | 38107a0cd119 | 7.9GB |
| minicpm-v:latest | c92bfad01205 | 5.5GB |
| bge-m3:latest | 790764642607 | 1.2GB |
| shaw/dmeta-embedding-zh:latest | 55960d8a3a42 | 408MB |
| quentinz/bge-large-zh-v1.5:latest | bc8ca0995fcd | 651MB |
| qwen2.5:32b_ctx32k | 5e352cf6721e | 19GB |
| qwen2.5:32b | 9f13ba1299af | 19GB |
| qwen2:72b_ctx32k | 7b11bbd9819a | 47GB |
| glm4:latest | 5b699761eca5 | 5.5GB |
| qwen2:72b | 93563ef658b2 | 41GB |
| deepseek-llm:67b | 52e3a994907e | 38GB |
| llama3.1:70b | c0df3564cfe8 | 39GB |
| qwen2.5:72b | 424bad2cc13f | 47GB |
ctx32k后缀表示可支持长达32k tokens的输入长度,为本人单独编译的模型,非官方模型,精度无变化,但运算速度较慢。
4 文件内容解析
4.1 架构预置解析方案
本架构提供了几种常见的解析能力。
| 解析方法 | 支持格式 | 备注 |
|---|---|---|
| laws | Docx、PDF、Doc、txt | |
| Paper | ||
| General | Docx、PDF、xlsx、txt、html、json、Markdown | 支持表格 |
以Laws解析方法为例,以下为解析并添加到知识库的示例代码。
# 使用内置Laws解析方法
from parser_content import laws
# 指定文件解析Chunk
chunk = laws.chunk(r"E:\Rag-CKH\test_file\2022版煤矿安全规程.docx")
# 添加到数据库中
from model_link.OllamaEmbedding import OllamaEmbed
from knowledgebase.insert import addChunk
ollama_embedding = OllamaEmbed(model_name="bge-m3", base_url="172.20.200.181:11434")
addChunk(embd_mdl=ollama_embedding, chunk=chunk, knowledgebase_name="ckh")
其中,addChunk函数中
-
embd_mdl为Embedding模型,可自行传入指定的模型对象 -
chunk是使用内置解析方法类中的chunk函数的返回值,为本框架统一的格式,在后文二次开发中有详细的解释。 -
knowledgebase_name指定要操作的知识库,注意:请首先保证知识库已经创建
注意:文件名本身将作为知识库中的标识标题,即
docnm_kwd,例如上述实例代码则以2022版煤矿安全规程.docx为标识标题。
4.2 对解析功能的二次开发
本架构充分考虑到解析功能的“变化莫测”和多样性,开放了以下接口用于适配
导入坐标
from knowledgebase.chunkToData import chunkToData
接口介绍
def chunkToData(title, chunks, lang="Chinese"):
"""
将解析的文本列表转换为保存到知识库前的统一格式
@param title: 文档名
@param chunks: 文本列表
@param lang: 语言
@return:
"""
将字符串列表作为实参传入到chunks,再规定其title即可。所返回值可以用于addChunk函数。
综上,自行开发的解析功能请使解析结果为一个字符串列表,然后传入此接口即可存入知识库中。
5 Agent WorkFlow工作流
5.1 引言
工作流中常用的组件均位于workflow_component中, 实例化类后调用其run函数 即可。
已有组件的使用示例代码在workflow_eg中。
在后续版本中,计划在run函数的源码中加入注释,便于调用时查看形参实际含义。//To do
history 形参指对话历史,由字典列表组成,例如
history = [{"role": "user", "content": "用户的输入"}, {"role": "assistant", "content": "大模型的输出"}]
列表内的字典按照时间顺序(由旧到新)排列,role 为
user或assistant,最后一个字典的role需要为user
5.2 生成关键词KeywordExtract
- 示例代码
from workflow_component.keywords import KeywordExtract
from model_link.OllamaChat import OllamaChat
ollama_chat = OllamaChat(model_name="qwen2.5:32b_ctx32k", base_url="172.20.200.181:11434")
k = KeywordExtract()
k.run("我是一个博士生,我没有女朋友。", ollama_chat, 10)
- 示例代码返回值
博士生, 没有, 女朋友
- 形参含义
def run(self, ask, chat_mdl, top_n):
"""
获取关键词,多个关键词之间使用逗号隔开
@param ask:用户问题字符串
@param chat_mdl:Chat模型对象
@param top_n:提取top_n个关键词
@return:字符串,多个关键词之间用逗号隔开
"""
5.3 问题优化RewriteQuestion
- 示例代码
from workflow_component.rewrite import RewriteQuestion
rq = RewriteQuestion()
rq.run(history=[{"role": "user", "content": ask}], chat_mdl=ollama_chat)
- 形参含义
def run(self, history, chat_mdl):
"""
优化用户问题
@param history:对话历史的字典列表
@param chat_mdl:Chat模型对象
@return:字符串,优化后的用户问题
"""
5.4 问题分类Categorize
- 示例代码
from workflow_component.categorize import Categorize
ca = Categorize()
catd = {
"无关问题": {
"description": "用户的问题与煤矿规章制度无关",
"examples": """你好
你是谁创造的?
今天天气怎么样?"""
},
"煤矿生产安全相关制度": {
"description": "用户的问题与煤矿规章制度有关",
"examples": """安全设施设计需要作重大变更应当怎么做?
煤矿建设项目竣工投入生产或者使用前应当由谁验收?
煤矿企业主要负责人有什么职责?
未统计目标任务完成情况
爆破作业什么时候进行?
煤矿智能化建设的技术路线?"""
}}
ca.run(ask="明天的天气怎么样?", chat_mdl=ollama_chat, category_description=catd)
- 示例代码返回值
无关问题
- 形参含义
def run(self, ask, chat_mdl, category_description):
"""
问题分类
@param ask: 用户问题字符串
@param chat_mdl: Chat模型对象
@param category_description: 统一格式字典
@return: 字符串,问题类型
"""
- category_description格式 例如
catd = {
"无关问题": {
"description": "用户的问题与煤矿规章制度无关",
"examples": """你好
你是谁创造的?
今天天气怎么样?"""
},
"煤矿生产安全相关制度": {
"description": "用户的问题与煤矿规章制度有关",
"examples": """安全设施设计需要作重大变更应当怎么做?
煤矿建设项目竣工投入生产或者使用前应当由谁验收?
煤矿企业主要负责人有什么职责?
未统计目标任务完成情况
爆破作业什么时候进行?
煤矿智能化建设的技术路线?"""
}}
即,第一层字典内键为问题类型,值为第二层字典,其中有description对此问题类型的简要描述、examples示例。
5.5 知识库召回Retrieval
- 示例代码
from workflow_component.jiansuo import Retrieval
re = Retrieval()
ref = re.run(query=a, embd_mdl=ollama_embedding, rerank_mdl=None, similarity_threshold=0.2,
keywords_similarity_weight=0.5, top_n=8, top_k=1024, empty_response="", knowledgebase_name="ckh")
- 示例代码返回值
返回值为Dataframe,以下仅列出表头字段以及首条数据。
| chunk_id | content_ltks | docnm_kwd | important_kwd | img_id | similarity | vector_similarity | term_similarity | vector | positions | content | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ba29bb4baba111efa13c00e04c680568 | 第一百四十九条生产水平和采(盘)区必须实行分区通风。... | 2022版煤矿安全规程.docx | [] | 0.574978 | 0.552391 | 0.597565 | [-0.9214252829551697, ...] | [] | 第一百四十九条 生产水平和采(盘) 区必须实行分区通风。... |
对于各个字段的含义不必多言。
- 形参含义
def run(self, query, embd_mdl, rerank_mdl, similarity_threshold, keywords_similarity_weight, top_n, top_k,
empty_response, knowledgebase_name, **kwargs):
"""
知识检索
@param query: 用户问题或检索关键词
@param embd_mdl: Embedding模型
@param rerank_mdl: Rerank模型(可为None)
@param similarity_threshold: 相似度阈值
@param keywords_similarity_weight: 关键词相似度权重
@param top_n: 取得分前n的Chunk
@param top_k: 取得分前k个Chunk送入Rerank
@param empty_response: 未检索到时的空返回
@param knowledgebase_name: 知识库名
@param kwargs: 无
@return:
"""
5.6 生成回答Generate
- 示例代码
from workflow_component.generate import Generate
# 回答问题
for temp in ge.stream_output(history=[{"role": "user", "content": a}], chat_mdl=ollama_chat, retrieval_res=ref,
embd_mdl=ollama_embedding,
prompt="""你是煤矿安全员,你只能依据后文给你的参考文本材料回答用户问题,不能使用自己的知识,严格按照要求作答。
你的工作是根据参考文本材料的内容以及文本材料的文件名称,一步一步地思考,按照以下步骤和要求完成任务。
请记住:思考过程应该是原始的、有机的和自然的,捕捉真实的人类思维流程,而不是遵循结构化的格式;这意味着,你的思维应该更像是一个意识流。
以下是思考过程:
1、首先默认用户的所有问题都是在询问参考文本材料中的相关规定,不能用其它知识进行作答。
2、然后针对用户提出的问题找到参考文本材料中的依据,注意专业名词的准确性,如果有多个相关的依据,请分别作答。
3、然后请用找到的依据原文作为依据,开始解答用户问题的答案,回答时合理分段,找到的每个相关依据使用以下格式:
"XXX(文件名)规定:XXX。
因此XXX(详细解答用户问题)。"
4、然后猜测三个用户接下来想问的问题,分段换行回答,使用以下格式:
"如果回答不够准确或检索的文件不正确,猜测您可能想追问的问题有:
1.XXX?
2.XXX?"
5、最后换行输出以下结束语:
"西安科技大学智能系统安全与控制研究所发布。鲁ICP备2023026495号(仅用于个人开发)"
以下是参考文本材料
{input}""", cite=True, input=ref_s):
print(temp)
- 形参含义
def stream_output(self, history, chat_mdl, retrieval_res, embd_mdl, prompt, max_tokens=512, temperature=0.50,
top_p=0.50, presence_penalty=0.40, frequency_penalty=0.70, cite=False, sse=False, **kwargs):
"""
生成回答-流式输出
@param history:对话历史
@param chat_mdl:Chat模型对象
@param retrieval_res:知识库召回Retrieval的返回值,若形参cite为FALSE,则可以为FALSE
@param embd_mdl:Embedding模型对象
@param prompt:提示词
@param max_tokens:最大Token值
@param temperature:详见超参数-温度
@param top_p:详见超参数-top p
@param presence_penalty:详见超参数-出现惩罚
@param frequency_penalty:详见超参数-频率惩罚
@param cite:是否输出引用来源,若为TRUE,则retrieval_res不能为空
@param sse:迭代是否满足SSE格式(用于EventSourceResponse)
@param kwargs:prompt中的变量
@return:流式输出迭代器
"""
-
流式输出说明
请注意,本组件的输出方式为流式输出,即以迭代器的形式按Token实时返回最完整的答案,调用函数时需要在迭代语句中。
若需要结合FastAPI实现流式输出,请使用
EventSourceResponse并在调用stream_output时设置形参sse为True
以下为FastAPI实现流式输出的示例代码
# 此API示例仅为了给出流式输出的核心代码,并未实现完整的流程。
from fastapi import FastAPI
from sse_starlette.sse import EventSourceResponse
from fastapi.middleware.cors import CORSMiddleware
from typing import Dict
import uvicorn
from workflow_component.generate import Generate
from model_link.OllamaChat import OllamaChat
ollama_chat = OllamaChat(model_name="qwen2.5:32b_ctx32k", base_url="172.20.200.181:11434")
ge = Generate()
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"]
)
@app.post("/chat")
async def response(data: Dict):
history = data['history']
return EventSourceResponse(ge.stream_output(history=history, chat_mdl=ollama_chat,
retrieval_res=None,
embd_mdl=None,
prompt="""你是煤矿安全员,你只能依据后文给你的参考文本材料回答用户问题,不能使用自己的知识,严格按照要求作答。
你的工作是根据参考文本材料的内容以及文本材料的文件名称,一步一步地思考,按照以下步骤和要求完成任务。
请记住:思考过程应该是原始的、有机的和自然的,捕捉真实的人类思维流程,而不是遵循结构化的格式;这意味着,你的思维应该更像是一个意识流。
以下是思考过程:
1、首先默认用户的所有问题都是在询问参考文本材料中的相关规定,不能用其它知识进行作答。
2、然后针对用户提出的问题找到参考文本材料中的依据,注意专业名词的准确性,如果有多个相关的依据,请分别作答。
3、然后请用找到的依据原文作为依据,开始解答用户问题的答案,回答时合理分段,找到的每个相关依据使用以下格式:
"XXX(文件名)规定:XXX。
因此XXX(详细解答用户问题)。"
4、然后猜测三个用户接下来想问的问题,分段换行回答,使用以下格式:
"如果回答不够准确或检索的文件不正确,猜测您可能想追问的问题有:
1.XXX?
2.XXX?"
5、最后换行输出以下结束语:
"西安科技大学智能系统安全与控制研究所发布。鲁ICP备2023026495号(仅用于个人开发)"
""", cite=False, sse=True))
log_config = uvicorn.config.LOGGING_CONFIG
log_config["formatters"]["access"]["fmt"] = "%(asctime)s - %(levelname)s - %(message)s"
log_config["formatters"]["default"]["fmt"] = "%(asctime)s - %(levelname)s - %(message)s"
uvicorn.run(app, host="59.74.169.90", port=8080, log_config=log_config)
-
提示词工程
提示词中需要制定其身份、任务、思维过程等,可变变量使用{}包含,例如上述示例代码中的{input}。
在调用
stream_output时,可以直接在最后一个实参中传入参数,例如input=
5 SSE流式输出的VUE解释器
npm安装@microsoft/fetch-event-source、md-editor-v3
以下为示例代码。
- 显示Latex数学公式
- 显示引用
- 显示表格
- 自动纠错不卡顿
<template>
<textarea v-model="state.ask" style="width: 40vw;font-size: large;"></textarea>
<button
@click="getMsg" v-if="!state.loading">发送
</button>
<MdPreview :modelValue = "state.content" / >
< p
v -
if= "state.ref_content.length!=0" > 以下是参考文献:
</p>
<div v-for="(item,index) in state.ref_content">
<MdPreview
:modelValue="state.ref_title[index]"/>
<MdPreview
:modelValue="item"/>
</div>
<MdPreview :modelValue = "state.ref" / >
< /template>
<script setup>
import {ref, reactive, computed, onMounted, watch} from "vue";
import {fetchEventSource} from "@microsoft/fetch-event-source";
import {MdPreview, MdCatalog} from "md-editor-v3";
let state = reactive({
content: '',
loading: false,
ref_title: [],
ref_content: [],
data: [],
ask: "现在工作面最大值为Emax=1000J,总能量:∑E=10000J/每5m推进度,是什么危险状态?"
})
const getMsg = () => {
state.ref_title = []
state.ref_content=[]
state.data=[]
let ctrlAbout = new AbortController()
state.loading = true
let url = 'http://59.74.169.90:8080/chat'
let dataInfo = {
"ask": state.ask
} //请求入参
fetchEventSource(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
"X-Access-Token": '',//你的=token
"Cache-Control": 'no-cache',
"Connection": 'keep-alive',
},
signal: ctrlAbout.signal,
body: JSON.stringify(dataInfo),//请求入参
openWhenHidden: true,//默认为false,监听visibilitychange,当页面不可见时关闭连接,当页面重新可见时重新打开连接。
onmessage(event) {
try {
//根据返回值进行内容拼接
state.content = (JSON.parse(event.data)).content
console.info(JSON.parse(event.data))
state.data = JSON.parse(event.data)
} catch (e) {
console.warn(e)
}
},
onclose() {
state.loading = false
try {
dealRef()
} catch (e) {
console.warn(e)
}
return
//请求完成自动关闭
},
onerror(err) {
console.warn(err)
return
},
});
}
const dealRef = () => {
const regex = /##\d\$\$/g;
let ref = []
let k = 1;
state.content = state.content.replace(regex, (a) => {
var numbers = a.match(/\d+/g);
numbers = parseInt(numbers)
ref.push(numbers)
console.info(ref)
return " **[" + (k++).toString() + "]**"
})
for (let i = 0; i < ref.length; i++) {
state.ref_title.push(" **[" + (i + 1).toString() + "]** " + removeAfterDot(state.data.reference.chunks[ref[i]].docnm_kwd))
state.ref_content.push(state.data.reference.chunks[ref[i]].content)
console.info(ref)
}
}
const removeAfterDot = (str) => {
return str.replace(/\..*/, '');
}
</script>
<style>
table, th, td {
border: 1px solid black;
text-align: center;
border-collapse: collapse;
}
</style>
6 API构建示例
- 使用FastAPI构建
- 能够跨域请求
- 知识召回等可并发可共享资源
# 此API示例仅为了给出流式输出的核心代码,并未实现完整的流程。
from fastapi import FastAPI
from sse_starlette.sse import EventSourceResponse
from fastapi.middleware.cors import CORSMiddleware
from typing import Dict
import uvicorn
from workflow_component.generate import Generate
from model_link.OllamaChat import OllamaChat
ollama_chat = OllamaChat(model_name="qwen2.5:32b_ctx32k", base_url="172.20.200.181:11434")
ge = Generate()
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"]
)
@app.post("/chat")
async def response(data: Dict):
history = data['history']
return EventSourceResponse(ge.stream_output(history=history, chat_mdl=ollama_chat,
retrieval_res=None,
embd_mdl=None,
prompt="""你是煤矿安全员,你只能依据后文给你的参考文本材料回答用户问题,不能使用自己的知识,严格按照要求作答。
你的工作是根据参考文本材料的内容以及文本材料的文件名称,一步一步地思考,按照以下步骤和要求完成任务。
请记住:思考过程应该是原始的、有机的和自然的,捕捉真实的人类思维流程,而不是遵循结构化的格式;这意味着,你的思维应该更像是一个意识流。
以下是思考过程:
1、首先默认用户的所有问题都是在询问参考文本材料中的相关规定,不能用其它知识进行作答。
2、然后针对用户提出的问题找到参考文本材料中的依据,注意专业名词的准确性,如果有多个相关的依据,请分别作答。
3、然后请用找到的依据原文作为依据,开始解答用户问题的答案,回答时合理分段,找到的每个相关依据使用以下格式:
"XXX(文件名)规定:XXX。
因此XXX(详细解答用户问题)。"
4、然后猜测三个用户接下来想问的问题,分段换行回答,使用以下格式:
"如果回答不够准确或检索的文件不正确,猜测您可能想追问的问题有:
1.XXX?
2.XXX?"
5、最后换行输出以下结束语:
"西安科技大学智能系统安全与控制研究所发布。鲁ICP备2023026495号(仅用于个人开发)"
""", cite=False, sse=True))
log_config = uvicorn.config.LOGGING_CONFIG
log_config["formatters"]["access"]["fmt"] = "%(asctime)s - %(levelname)s - %(message)s"
log_config["formatters"]["default"]["fmt"] = "%(asctime)s - %(levelname)s - %(message)s"
uvicorn.run(app, host="59.74.169.90", port=8080, log_config=log_config)
7 性能评估
对于SSE流式输出Post请求市面上还没有成熟的压力测试工具,以下为本人编写的测试代码。
import json
import requests
import time
import random
def sse_ask(task):
url = "http://59.74.169.90:8080/chat" #API地址
random_num1 = random.randint(1, 190129)
random_num2 = random.randint(1345, 3454555)
data = {
"ask": f"现在工作面最大值为Emax={random_num1}J,总能量:∑E={random_num2}J/每5m推进度,是什么危险状态?"} #用户问题
print(data)
headers = {
'Accept': 'text/event-stream',
'Content-Type': 'application/json'
}
json_data = json.dumps(data)
response = requests.post(url, data=json_data, headers=headers, stream=True)
if response.status_code == 200:
buffer = ''
for line in response.iter_lines(decode_unicode=False):
line = line.decode('utf-8')
if line.startswith('data:'):
data = line[5:].strip()
if data == '[DONE]':
break
buffer += data
# current_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# str_t=current_time+":任务"+str(task)+":"
# print("\033[31m",str_t,"\033[0m",len(json.loads(buffer)['content']))
update_process(task, len(json.loads(buffer)['content']))
elif line.strip() == '':
if buffer:
buffer = ''
update_process(task, "done")
else:
raise Exception(f"请求失败,状态码:{response.status_code}")
dict = {}
def update_process(task, len):
global dict
current_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
if len == "done":
dict["任务" + str(task)] = current_time + "完成"
else:
dict["任务" + str(task)] = dict.get("任务" + str(task), 0) + 1
text_to_append = '\n' + current_time + ":" + str(dict)
with open('log30-32b.txt', 'a', encoding='utf-8') as file: #日志保存到txt
file.write(text_to_append)
print(current_time + ":" + str(dict))
import threading
def main():
vu_num = 30 #并发用户数量
threads = []
for i in range(vu_num):
t = threading.Thread(target=sse_ask, kwargs={"task": i})
threads.append(t)
t.start()
for t in threads:
t.join()
if __name__ == "__main__":
main()
8 工作总结
本工作旨在构建一个灵活多样的Rag架构,同时又能够满足各模块急速发展的需求,二次开发接口明确,能够满足大部分场景需求。
- 对于多模态的支持,本文暂未提及,因为其实际功能似乎意义不大。
- 大小协同等推荐集成FastAPI,实现接口耦合。
- 微调模型经过格式转换生成Ollama格式即可直接被本框架调用。
本工作源码暂不公开,仅用于开发参考。