摘要
本文对我校A100服务器进行配置,利用 Docker容器 实现多用户的共享使用,同时实现远程运维、硬件资源监控等高权限管理操作。
文中部分敏感信息不予公布,本文仅用作技术日志,不作为服务器维护参考。
更新日志
- 2024.10.28 考察当前对高性能算力服务器单机/集群的多人共享方案
- 2024.10.29 抛弃开源管理平台,转入手撕Docker。
- 2024.10.30 搭建基本完成,准备投入灰度上线。
- 2024.12.02 优化Ollama并发能力。
- 2024.12.04 增加nvidia-container-toolkit安装部分
- 2025.01.02 优化了Ollama安装命令
目录
背景依托
博0阶段横向
服务器配置
- 浪潮NF5280M6
- 2*Intel Xeon Platinum 8352V(32C,2.1GHz)
- 4*32G DDR4
- 2*960GB SSD(SATA) 后续会扩展SSD
- 出厂Raid1已关闭
- 2千兆电口+2千兆光口
- 2*1300W 380V电源供给
- A100 80G
Root用户
修改root用户密码
sudo -i
passwd root
按照提示输入新的密码,此处设置为不予公开
配置远程运维面板
此处使用RedHat的开源项目——Cokpit
安装
sudo apt install cockpit cockpit-podman
激活与启动
sudo systemctl enable --now cockpit.socket
查看运行状态
sudo systemctl status cockpit --no-pager -l
默认端口9090的防火墙放行
sudo ufw allow 9090
修改默认端口*
cat /usr/lib/systemd/system/cockpit.socket
配置文件中ListenStream即为监听端口。
修改完成后重启服务
sudo systemctl daemon-reload
sudo systemctl restart cockpit.socket
sudo systemctl restart cockpit.service
运维基础
GPU监控
- nvidia自带监控
其中,-n参数配置刷新速率,单位为秒。watch -n 1 nvidia-smi - nvtop工具
- 安装
sudo apt install nvtop- 运行
nvtop
容器资源监控
docker stats
Docker容器
安装
设置全局Docker源
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
安装最新版本Docker
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
配置nvidia-container-toolkit
为了使Docker容器能够调用宿主机的Cuda,需要安装nvidia-container-toolkit。
这是最新用法,请忽略
nvidia docker、nvidia docker2
注意: 请设置DNS为114.114.114.114,推荐打开IPv6。
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
免sudo运行docker命令*
sudo gpasswd -a 用户名 docker
sudo service docker restart
newgrp - docker
维护
使用软链接修改默认存储位置*
- 查看默认存放位置
sudo docker info | grep "Docker Root Dir"
- 停止Docker服务
systemctl restart docker
service docker stop
- 迁移数据
mv /var/lib/docker /data/docker
其中,/var/lib/docker是系统Docker默认数据文件存储位置,/data/docker是想要迁移到的新位置。
- 创建软链接
ln -sf /data/docker /var/lib/docker
通过修改配置文件修改默认存储位置*
- 修改Docker配置
- 第一种方法:修改
/etc/default/docker配置文件
OPTIONS=--graph="/data/docker" -H fd://- 第二种方法:修改运行时配置文件
此方法仅适用于Docker版本$\geq 1.12$
增加JSON属性vim /etc/docker/daemon.json"graph": "/data/docker" - 第一种方法:修改
- 启动Docker服务
sudo systemctl daemon-reload
sudo systemctl restart docker.service
镜像与容器
国内Docker镜像站
- 单次使用
在
docker pull的镜像名前增加镜像站的域名 - 永久更换
echo '{
"registry-mirrors": ["镜像站地址"]
}' | sudo tee /etc/docker/daemon.json
恢复镜像名
docker tag 镜像站域名/<namespace>/<imagename>:<tag> <namespace>/<imagename>:<tag>
科研适用镜像
- Docker Hub-Nvidia:已经安装好Cuda环境的Linux镜像,此链接已经筛选了Ubuntu。
base: Includes the CUDA runtime (cudart)即包含CUDA的运行库。
runtime: Builds on the base and includes the CUDA math libraries, and NCCL. A runtime image that also includes cuDNN is available.多了CUDA的数学库、cuDNN等。
devel: Builds on the runtime and includes headers, development tools for building CUDA images. These images are particularly useful for multi-stage builds.CUDA的开发专用镜像。
- Nvidia NGC-Pytorch 推荐使用:已经配置好Pytorch以及常用深度学习库,可以直接使用jupyter notebook开启jupyter服务器。
-
Nvidia NGC-Tensorflow推荐使用:已经配置好Tensorflow以及常用深度学习库,可以直接使用jupyter notebook开启jupyter服务器。
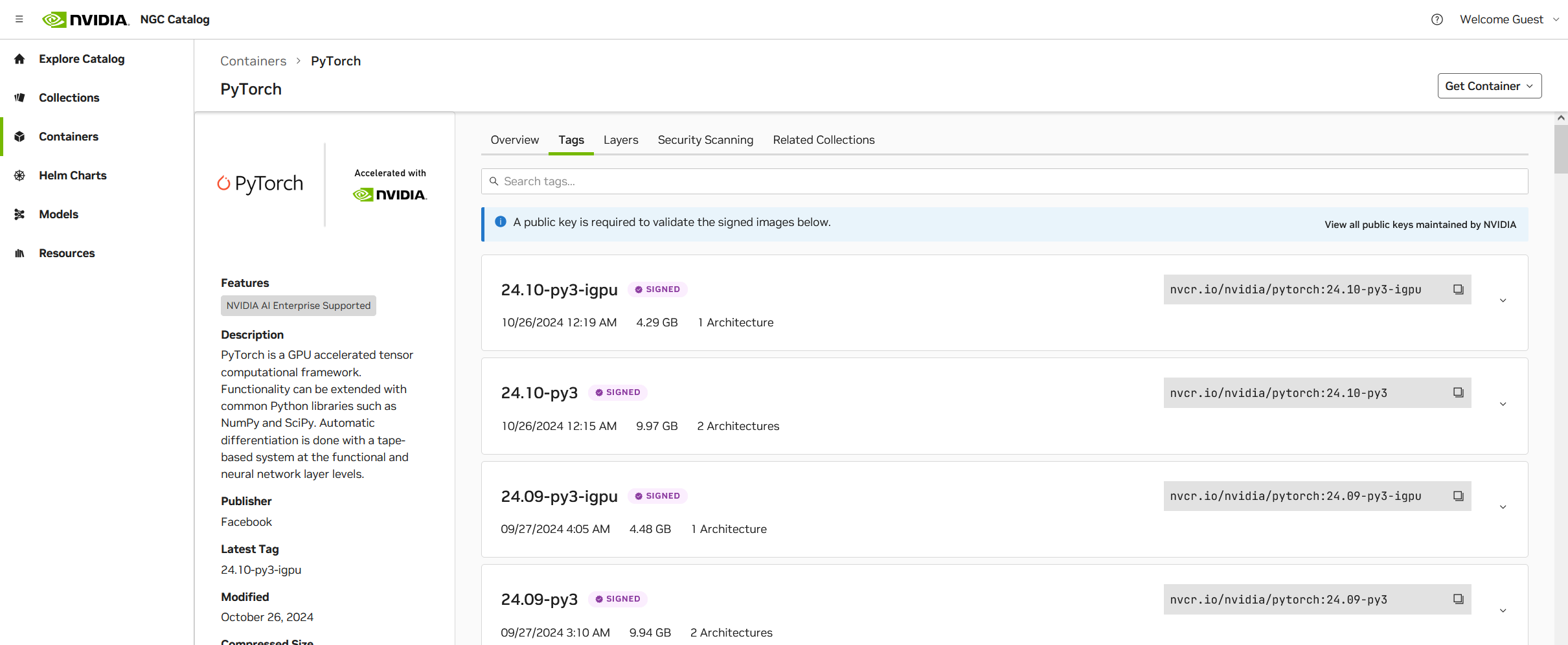
容器内初始配置
安装常用维护工具
- 检查是否能够与宿主机Nvidia显卡通信
nvidia-smi
- 安装netstat工具
apt-get install net-tools
- 修改root用户密码
passwd root
常用状态查询命令
- 查询端口占用情况
netstat -anp | grep 22
开启容器内SSH服务
- 安装openssh
apt-get update
apt-get install openssh-server
- 修改sshd配置
vim /etc/ssh/sshd_config
去除PermitRootLogin的注释,并修改配置为yes
PermitRootLogin yes
- 启动ssh服务
service ssh start
Dockerfile自动化
以上工作均可使用Dockerfile集成,自动创建相应 镜像。
在一个新建文件夹中,创建Dockerfile。
#这里的基础镜像可以替换
FROM nvcr.io/nvidia/pytorch:24.10-py3 AS base
USER root
RUN apt-get update
RUN apt-get install -y net-tools
RUN apt-get install -y openssh-server
#初始密码为xustckh
RUN echo "root:xustckh" | chpasswd \
&& sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config \
&& sed -i 's/^#\(PermitRootLogin.*\)/\1/' /etc/ssh/sshd_config
#设置SSH服务自动启动脚本
COPY start_ssh.sh /root/start_ssh.sh
RUN chmod +x /root/start_ssh.sh
RUN sed -i '$a\if [ -f /root/start_ssh.sh ]; then ' /root/.bashrc \
&& sed -i '$a\ . /root/start_ssh.sh' /root/.bashrc \
&& sed -i '$a\fi' /root/.bashrc
创建start_ssh.sh
#!/bin/bash
LOGTIME=$(date "+%Y-%m-%d %H:%M:%S")
echo "[$LOGTIME] startup run..." >>/root/start_ssh.log
service ssh start >>/root/start_ssh.log
在当前目录下执行终端命令
sudo docker build -t 镜像名 .
其中,-t表示镜像名,.表示上下文在当前目录下。
以上步骤创建的容器能够自动启用SSH服务。
共享容器的分配与使用
当有用户申请算力资源时,若无特殊说明,将默认使用已经测试成熟的较新NGC Docker镜像作为基础镜像。
-
容器映射说明
默认情况下需要映射容器内的端口有
服务 容器内端口 SSH 22 Jupyter 8888
新建容器
docker run --name 容器名 -itd -p SSH外漏端口号:22 -p Jupyter外漏端口号:8888 -v 主机目录:容器内目录 --restart=always 自编译镜像名 /bin/bash
- 限制资源(软性限制)
-
限制CPU占用率($\le1$)或核数量($\geq1$):
--cpus="1.5" -
限制内存:
-m 16g - 限制显存:不建议
-
限制CPU占用率($\le1$)或核数量($\geq1$):
进入容器
sudo docker exec -it 容器名 /bin/bash
容器持久化
当有对环境、数据文件有保存需求时
docker commit 容器名 镜像名
垃圾镜像的删除*
编译镜像出现重名情况时,原有镜像会被更名为<none>,核对好这些镜像并没有被容器调用时,使用以下命令清理。
docker rmi -f $(docker images | grep none | awk '{print $3}')
Ollama的安装
下载与安装
在官方Github的Release中下载最新版本的ollama-linux-amd64.tgz
输入以下命令安装
sudo tar -C /usr -xzvf ollama-linux-amd64.tgz
配置服务
创建新用户
sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
sudo usermod -a -G ollama $(whoami)
创建新文件
sudo vim /etc/systemd/system/ollama.service
编辑内容为
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_NUM_PARALLEL=5" # 并行数量,这个数量越大模型在并行处理响应时间越长,设置为5较好,默认是1或者4
#Environment="OLLAMA_KEEP_ALIVE=5m" # 运行模型保留时长,ollama有模型自动卸载功能,默认是5m,5分钟
Environment="OLLAMA_MAX_LOADED_MODELS=10" # ollama可以同时加载的模型数量。默认是3*GPU数量或者CPU推理的是3
Environment="OLLAMA_MAX_QUEUE=2048" # 在繁忙时最大请求数,超过这个数的其它请求会被拒绝,默认是512
[Install]
WantedBy=default.target
其中的
Shell Environment="OLLAMA_HOST=0.0.0.0:11434"用于放行外部访问
其它 启动服务
sudo systemctl daemon-reload
sudo systemctl enable ollama
sudo systemctl start ollama
模型配置
ollama服务内置上下文长度为2048,且无法通过传参的方式修改(因此使用ollama时,总Token数量设置无法生效),导致相关信息被截断,从而影响问答效果。
解决方案为手动调整大模型参数并重新编译为一个新的模型。
首先将待修改模型的模型配置文件导出
ollama show --modelfile qwen2:72b > Modelfile
然后使用vim修改Modelfile,添加一行
PARAMETER num_ctx 32000
使用修改后的模型配置编译一个新的模型并存入Ollama的本地仓库
ollama create -f Modelfile qwen2:72b_ctx32k
日常维护
升级
升级前需要停止服务
sudo systemctl stop ollama
sudo systemctl disable ollama
然后重新启动服务
sudo systemctl daemon-reload
sudo systemctl enable ollama
查看运行状态
sudo systemctl status ollama